pg下载 一篇文章教会你利用Python网络爬虫抓取百度贴吧评论区图片和视频
【一、项目背景】
全球最大的中文交流平台是百度贴吧,你可曾像我这般,有时瞧见评论区的图片就想予以下载?抑或是瞅见一段视频就打算开展下载? , 。
今天,小编带大家通过搜索关键字来获取评论区的图片和视频。
【二、项目目标】
实现把贴吧获取的图片或视频保存在一个文件。
【三、涉及的库和网站】
1、网址如下:
这明显不是一句具体话语来进行改写哦,请你重新提供句子描述等进行编辑要求,仅这个链接形式无法按照上述规范来处理呢 。2、涉及的库:requests、lxml、urrilb
【四、项目分析】
1、反爬措施的处理
于早些时候进行测试之际发现,该网站针对反爬虫所采取的处理措施数量繁多,经过测试察觉到存在以下几个措施,。
直接运用requests库pg下载麻将胡了,于未设置任何header的情形下,网站径直不返回数据。
2) 同一个IP相继展开了超四十次的接入访问,径直对IP进⾏封禁,其实我最初的IP就是因为诸如上述原因如此这般遭遇的封禁。
想要解决这两个问题,最后历经了一番研究,而后运用以下方法,如此便是能够有效解决的 。
取得属于正常范畴的http请求头,之后呢,当进行requests请求之际,对此类常规的http请求头做出设置 。
2、如何实现搜索关键字?
依靠网址,我们能够发觉,只要于kw=()这儿,于那括号里头键入你打算搜索的内容就行。如此一来,便能够拿一个{}去替换它,往后我们借助循环对它予以遍历。
【五、项目实施】
1、去构造一个名为BaiduImageSpider的类,去定义一个主方法main以及初始方法init。将需要使用的,那些库给导入进去。

2、准备url地址和请求头headers 请求数据。
import requests
from lxml import etree
from urllib import parse
类,称作,百度图片爬虫工具,对象,(其中)对象包含在括号内,object(这个英文单词在这里表示对象),括号。
自定义一个方法,该方法名为__init___,其带有一个用于接收参数ties ba_name___的参数 ,最后的标点符号为冒号。
tieba_name这个输入的名字 将其 设为 self.tieba_name ,这个self.tieba_name ,是这样设定的 。
自分のURLに「http://tieba.baidu.com/f?kw={}&ie=utf-8&pn =0」を設定する 。
self.headers = {
存在一个关于User - Agent的表述为,Mozilla/4.0这点,此为兼容情况的体现,即跟MSIE 8.0兼容,有Windows NT 6.1系统环境,处于WOW64状态下,Trident/4.0在其中发挥作用,还有SL CC2、.NET CLR 2.0.50727、.NET CLR 3.5.30729、.NET CLR 3.0.30729这些相关配置pg下载赏金下载,Media Center PC 6.0也被包含其中,以及.NET4.0C、InfoPath.3也一同构成了该表述的具体内容。 。
进行发送请求这一行为,之后对所取得的情况来获取以响应目的为导向的结果 。
构建一个名为 def 的作用域体,生成一个名为 get_parse_page 的实体,此实体需接收两个参数来执行相应动作,这两个参数表现为这样的形式。
通过发出请求获得内容随后转码,具体是,向该网址发送请求,借助自身头部参数,得到的内容,进行解码,转成utf - 8编码形式,最终赋值给html 。
parse_html = etree.HTML(html)
变量r_list的值,是通过,应用parse_html的xpath方法来获取的、对应xpath路径下找到的内容,所构成的集和,。
return r_list
def main(self):
自我的链接等于,自我的链接按照自我所提供的贴吧名称进行格式化输出,通过这种形式被确定 😒。 (此句添加了情绪表达类表述用于。
倘若当前模块的名称等于 '__main__' ,那么:
要查资讯,键入行须讯要你入输:")品求查入输要请("取输 = dne_wbroiu。
临时占位单词是等于,被特殊处理的单词经过另函所示这样的处理程序处理。,就得出了特殊用途字母的运算形式。,对吧。
蛛形纲动物、节肢动物代表蛛那种有两个明显体段、八条腿的生物体,等于百度图像爬虫、网络抓取工具,其抓取的是。
spider.main()
3、用xpath进行数据分析
3.1、chrome_Xpath插件安装
这里的使用中涉及到一个插件用于校验,它可以对我们所爬取的信息去进行快速的正确性检验,至于具体的安装方法则详细列示如下面这般。
用百度的方式去下载名为 chrome_Xpath_v2.0.2.crx 的内容,在 chrome 浏览器里输入 chrome://extensions/ 。

把chrome_Xpath_v2.0.2.crx通过直接拖动这种方式,放置到那个扩展程序页面 , 。
如果安装遭遇失败这种状况,会弹出显示“无法从该网站添加应用、扩展程序以及用户脚本”的框体提示,碰到此问题时,解决的办法是:开启开发者模式,把crx文件(直接地或者将后缀修改成rar)予以解压从而成为文件夹,于开发商者模式处点选加载已解压的扩展程序,挑选解压好的文件夹并选取,接着点取确定,如此安装便成功了。
3.2、chrome_Xpath插件使用
此前我们早就是已经将chrome_Xpath插件给安装妥当了的状态之下,紧接着我们等会儿便可用于即将要去使用它了 ,一是先把能够浏览网页的程序给打开,然后按一按那在键盘上特定的快捷键F12pg下载通道,二再是去选一下元素,就和下面所呈现这幅图一样 。
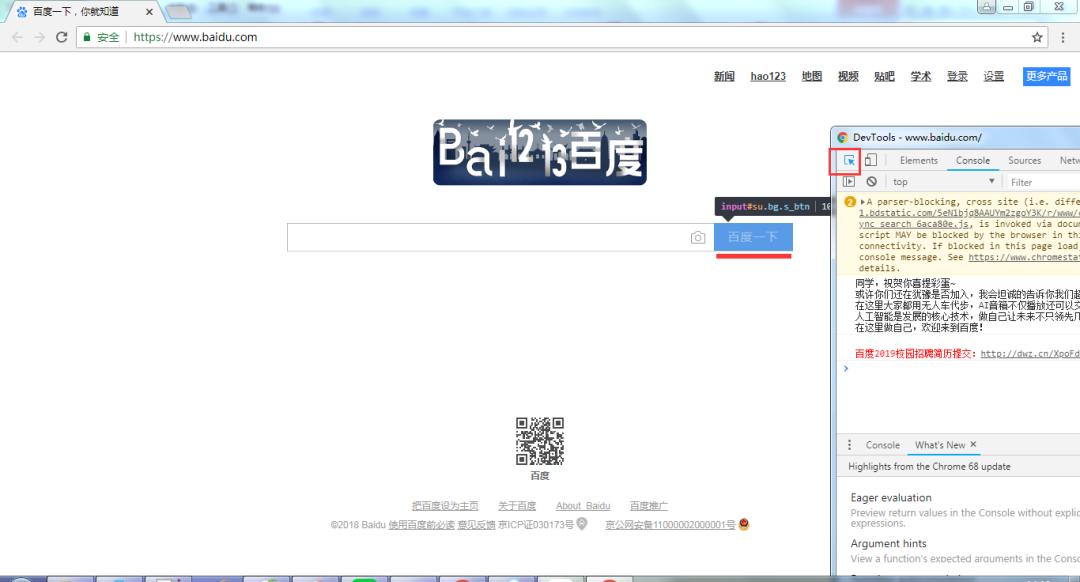
先是右键,之后经过选择,选的是“Copy XPath”,呈现模样像下图展现一般的样子,是这样的情况 。
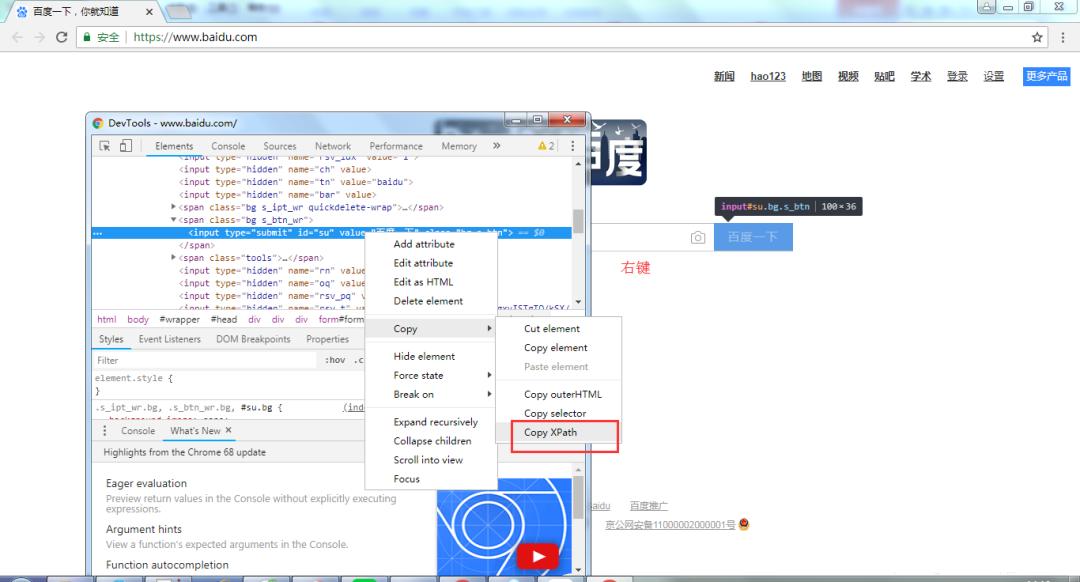
3.3、编写代码,获取链接函数。
就在上面的部分内容里,我们已经成功地获取到了链接函数的Xpath路径,紧接着,要去定义一个get_tlink获得链接函数,并且继承self,最终实现多页抓取。
4、保存数据
这儿定义一个用于将数据保存的write_image方法,情况如下所展现的样子。
把内容存到本地所具备的函数 ,关于将其存放在当地的函数内容,可依据某方面规范的那种函数 ,于本地进行存储的函数 。
定义,用于,书写成这样一种存在形式的,将某些东西,图像表示的,自身具备特性方法,这个东西的,是。
xpath = "//div
赋予那个类一个值,该值是字符串形式的 'd_post_content j_d_post_content clearfix',并且利用 @ 将它进行特定命名,对其施加赋予类并赋予属性名为@之后紧跟命名数值引号中内容的操作 。
/img
@class='BDE_Image'
/@src | //div
这是一个@class标识符,它被设置为与这个特定类名关联,这个类名使用单引号引发,它写的是 'video_src_wrapper。
这里并非正常 sentence结构 让修改的内容呀 请你提供正确表意的句子 我才能按照要求改写 你所给的这个 无法进行改写 。
for img_link in img_list:
requests.get函数里传入url指定img_link,及headers使用self.headers,返回内容得到的结果,赋给html 。
filename = "百度/"+img_link
在这样的状况之下,通过使用open函数将存放文件名的变量filename及代表二进制写入模式的'wb'作为参数传入,遂产生了文件对象f,进而以这种。
f.write(html)
print("%s下载成功" % filename)
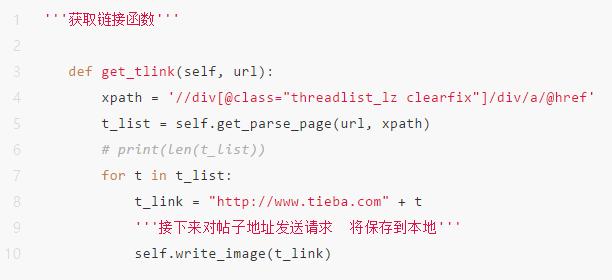
注:@data-video是网址中的视频,如下图所示。
【六、效果展示】
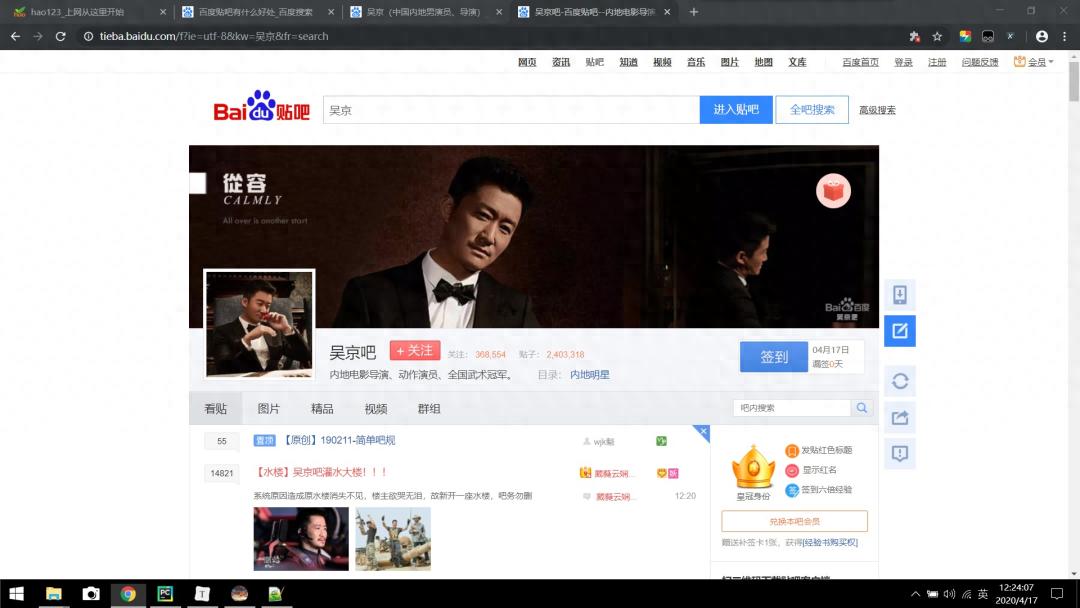
1、点击运行,如下图所示(请输入你要查询的信息):
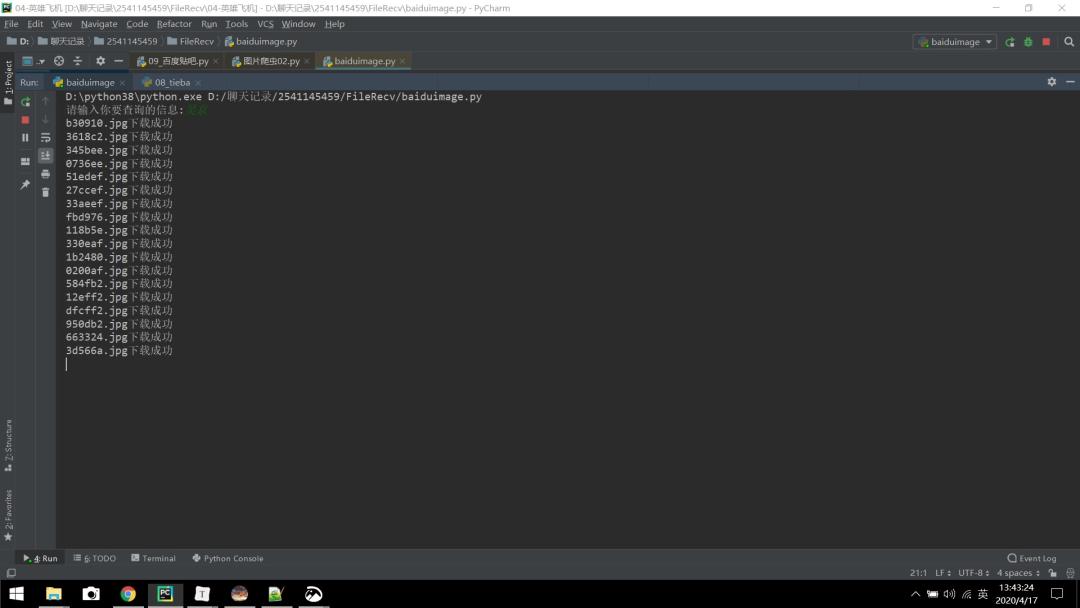
2、以吴京为例输入,回车:
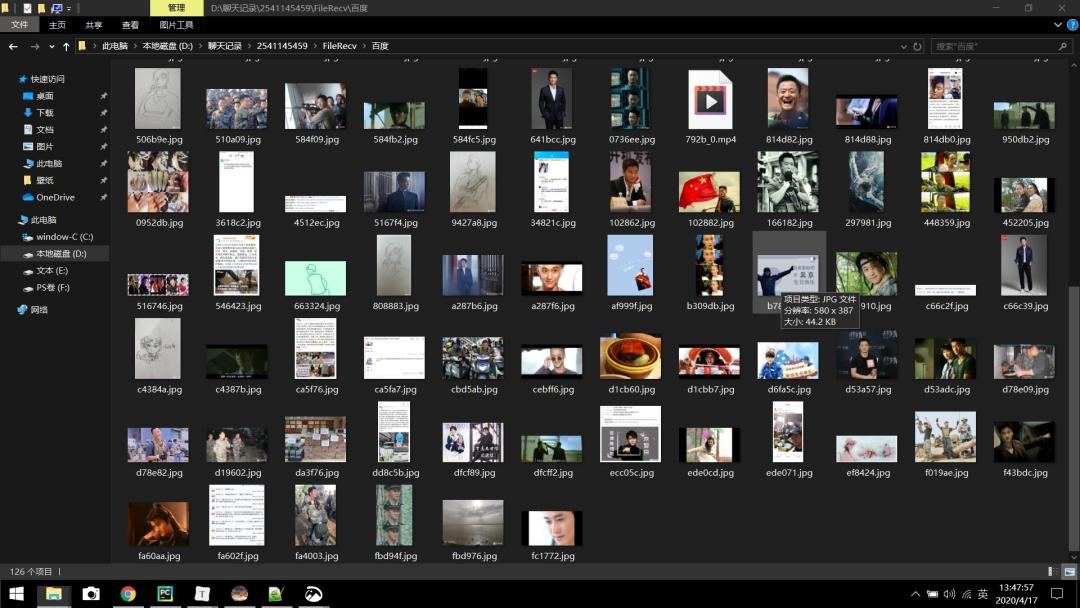
把图片下载,留存于一个叫作出“百度”的文件夹之中,对于这个特定的文件夹,你得预先就在本地完成新立工作。一定要记得要提前于此处代码的同一级别目录范围以内,来创建一个命名弄为“百度”的文件夹;不然的话,系统就没法寻觅到那一个文件夹,进而会报出找不到名为“百度”的这个文件夹的错误警报。
4、下图中的MP4就是评论区的视频。
【七、总结】
1、不太建议去大批量地抓取诸多数据过来,不然很容易因之而对服务器导致造成负载,只要稍微尝试一下就可以消停了。
2本次文本,靠着Python网络爬虫借助了爬虫库达成了对百度贴吧评论区的爬取就此对Python爬取百度吧的某些难点展开翔实讲解并给出有效的解决办法3诚挚地欢迎大家踊跃尝试有时见到别人做起很轻易可轮到自己动手去完成时却总会出现形形色色的问题千万不要眼馋技术又鄙视实践只有频繁操作才行更扎实地去参透有关事项需研习一下requests 库的应用以及爬虫程序的编制写出完整无误的句子并检查语法确保逻辑严密符合用户任务需求4借助这个项目能够更迅速地得以获取自身所想要的信息。关注私信【01】即可获取python资料。